.avif)
Marketing Data Sources: Your 2026 Guide to Growth


.avif)
You're probably dealing with this right now. A campaign looks strong on paper. The audience is defined, the copy is sharp, sales is waiting for meetings, and then performance comes back flat. The problem often isn't the creative or the channel. It's the data underneath the decision.
That happens when contact records are stale, firmographics are missing, lifecycle stages don't match reality, or targeting is built from channel dashboards that never connect to pipeline quality. In B2B, bad data doesn't just waste impressions. It sends SDRs after the wrong accounts, pollutes attribution, and creates compliance risk the moment someone asks where the record came from.
Marketing data sources matter because they decide what your team can trust. The strongest teams don't treat data as a loose collection of tools. They treat it as an operational hierarchy. Start with the data you own. Clean it. Govern it. Then enrich it with external signals that sharpen account selection, routing, and outreach without breaking compliance.
Table of Contents
- Why Your Marketing Is Only as Good as Your Data
- A simple way to think about the categories
- Comparison of marketing data source categories
Why Your Marketing Is Only as Good as Your Data
Most marketing problems show up as execution problems first. Low conversion rates. Weak handoff quality. Sales rejecting leads. Paid campaigns driving volume but not opportunities. But when you trace those issues back, the root cause is often broken source data.
That's why the conversation about marketing data sources isn't academic. It's operational. If your targeting logic comes from incomplete CRM fields, if your reporting comes from disconnected channel exports, or if your forms collect messy inputs that never get standardized, your team can't make reliable decisions.
Marketing measurement became more standardized as digital tools took over day-to-day planning and reporting. Foundational source categories now commonly include website analytics, social engagement, email performance, CRM records, and paid advertising metrics. The rise of Google Analytics as a default web analytics source was a major milestone because it pushed teams away from isolated channel reporting and toward integrated measurement across first-party and platform data, as described in Park University's overview of smarter marketing decisions.
In practice, that shift changed the job. Marketers no longer just need campaign reports. They need connected truth across traffic, lead creation, account qualification, opportunity movement, and revenue.
Practical rule: If a data source can't help your team improve targeting, attribution, or pipeline decisions, it's a reporting artifact, not a strategic asset.
For B2B teams, the hierarchy usually starts with CRM and owned conversion data, then moves outward to product, web, ad, financial, and enrichment layers. If you want a deeper look at how teams turn raw reporting into usable decision support, this guide to marketing data analysis is a useful companion.
First, Second, and Third-Party Data Explained
A simple way to think about the categories
The easiest way to explain data categories is with a kitchen analogy.
First-party data is what you grow in your own garden. You know where it came from, how fresh it is, and what went into it. In marketing, that means records from your CRM, website forms, email engagement, product usage, support conversations, and sales activity.
Second-party data is what a trusted neighbor shares directly with you. It still came from someone's own garden, but you received it through a relationship. In practice, this might be a partner sharing audience insights, event attendee data under agreed terms, or co-marketing information exchanged through a direct arrangement.
Third-party data is what you buy from a marketplace. It can help when you need breadth or enrichment, but you have less direct control over how it was collected, refreshed, or matched.
Those distinctions matter because every source category creates different trade-offs in control, scale, relevance, and compliance burden.
Comparison of marketing data source categories
| Characteristic | First-Party Data | Second-Party Data | Third-Party Data |
|---|---|---|---|
| Source | Collected directly by your company | Shared by a partner that collected it directly | Acquired from aggregators or external providers |
| Typical use cases | Lead management, lifecycle analysis, customer segmentation, attribution inputs | Partnership campaigns, channel collaboration, audience expansion with known context | Prospecting, enrichment, account research, market coverage |
| Control | Highest | Medium | Lowest |
| Relevance | Usually strongest for your pipeline and customer motion | Can be high if the partnership is tight | Varies widely by provider and use case |
| Scale | Limited by your own reach and traffic | Limited by partner scope | Often broader |
| Cost structure | Operational cost to collect, store, and govern | Negotiated access or exchange value | Commercial purchase or usage-based access |
| Accuracy risk | Comes from internal process quality | Depends on partner practices and field definitions | Depends on sourcing, refresh cadence, and match logic |
| Compliance consideration | You're directly responsible for consent, storage, and usage | Shared responsibility requires clear terms | Requires careful diligence on provenance, usage rights, and lawful processing |
A lot of teams make the same mistake. They chase third-party scale before they've cleaned first-party fundamentals. That usually creates more noise, not more pipeline.
Here's the practical order that works better:
- Start with owned data: CRM, forms, product usage, and lifecycle events should be usable before anything else.
- Add direct partnership data selectively: Use second-party sources when there's a clear campaign or account strategy behind them.
- Use third-party inputs to fill gaps: External data works best when it enriches records you already care about, instead of becoming your whole targeting model.
The value of a data source isn't how much it contains. It's how confidently sales and marketing can act on it.
When teams understand these categories clearly, they stop debating data in abstract terms and start asking better questions. Who collected this? How current is it? What decision will it support? What compliance obligations come with using it?
Why Your First-Party Data Is Your Goldmine
What sits inside first-party data
The most valuable data source in many B2B organizations is already inside the building. It's just underused.
First-party data includes more than a contact table in Salesforce or HubSpot. It covers the full trail your buyers leave with you. Form fills. Demo requests. Opportunity stage changes. Email engagement. Website behavior. Product activity. Renewal timing. Support interactions. Even the fields sales updates manually after discovery calls.
Each of those sources answers a different question:
- CRM records show account ownership, deal progression, lead source history, and lifecycle movement.
- Website analytics show what buyers explored before they raised a hand.
- Email engagement helps identify message relevance and timing.
- Product or trial data reveals buying intent and expansion potential in ways campaign metrics can't.
Why CRM deserves priority
One industry analysis makes a point many teams need to hear more often. It argues that CRM is the “most valuable data source” because it contains first-party data your company already owns, and it can reveal lifecycle patterns and customer behavior that generic channel dashboards miss. That same analysis also makes the practical recommendation teams often ignore. Start with what you already have before adding more tools. You can read that argument in The Brand Consultancy's article on overlooked growth data.
That lines up with how RevOps teams operate. If your CRM has weak job titles, duplicate accounts, inconsistent industry values, or missing handoff notes, adding external data won't fix the underlying process. It will just decorate the mess.
A common failure point starts even earlier, at capture. If inbound forms collect bad inputs, your first-party foundation decays at the top of the funnel. That's why it's worth reviewing secure web form submission practices before you worry about fancy enrichment workflows.
Field test: Audit the records attached to your last closed-won and closed-lost opportunities. You'll usually find that the useful segmentation clues were already present in your own systems, just not normalized or activated.
For B2B pipeline quality, first-party data does three jobs no external source can fully replace. It tells you who engaged. It tells you where they are in your buying process. And it tells you whether marketing activity moved into sales reality.
That's the goldmine. Not because it's glamorous, but because it's closest to truth.
Sourcing External Data Second and Third-Party
When external data helps
External data becomes useful when your internal picture is directionally right but incomplete.
Maybe your CRM tells you which accounts are in play, but not the buying committee around them. Maybe you know your best-fit customer profile, but not which adjacent markets resemble it. Maybe paid and outbound teams need broader coverage than inbound can generate on its own. That's where second-party and third-party sources enter the stack.
Second-party data is usually strongest when there's a direct business relationship behind it. Partner ecosystems, co-hosted webinars, channel programs, and publisher relationships can all generate information that's more context-rich than generic list purchases. The trade-off is reach. These sources can be highly relevant, but they don't usually scale broadly.
Third-party data flips that equation. You often get more coverage, more contacts, and more company-level context, but you need stricter standards for match quality, freshness, and compliant use. In practice, third-party data is best used to enrich and verify, not to replace your own operating system.
The most useful external source is often public
The most underrated external inputs aren't always commercial.
Secondary and public sources have been part of marketing intelligence for a long time. Common examples include government agencies, industry associations, educational institutions, the U.S. Census Bureau, and international datasets such as the UN, World Bank, and WTO. These sources remain valuable for market sizing, demand benchmarking, and validating assumptions across geographies. The Lumen Learning reference also notes that World Bank Data covers 100+ countries and WTO Data spans 100+ member countries, which makes them useful for cross-market analysis in a way many campaign platforms aren't. See Lumen Learning's overview of marketing data sources.
That matters because external data shouldn't only answer “who can I contact?” It should also answer:
- Is this market large enough to pursue?
- Are we seeing company-level demand, or broader category movement?
- Does our ICP logic hold across regions or segments?
If your use case is list expansion, enrichment tools can help connect account names to more complete records. If that's your focus, this overview of B2B data enrichment tools is a practical reference point.
What doesn't work is buying external data without a clear activation path. If the team can't say how the new fields will improve routing, segmentation, or outreach, the source becomes shelfware.
Measuring What Matters Data Quality Metrics
A large source catalog doesn't mean much if the records inside it can't support action. Data quality is what turns a source into something marketing and sales can safely use.
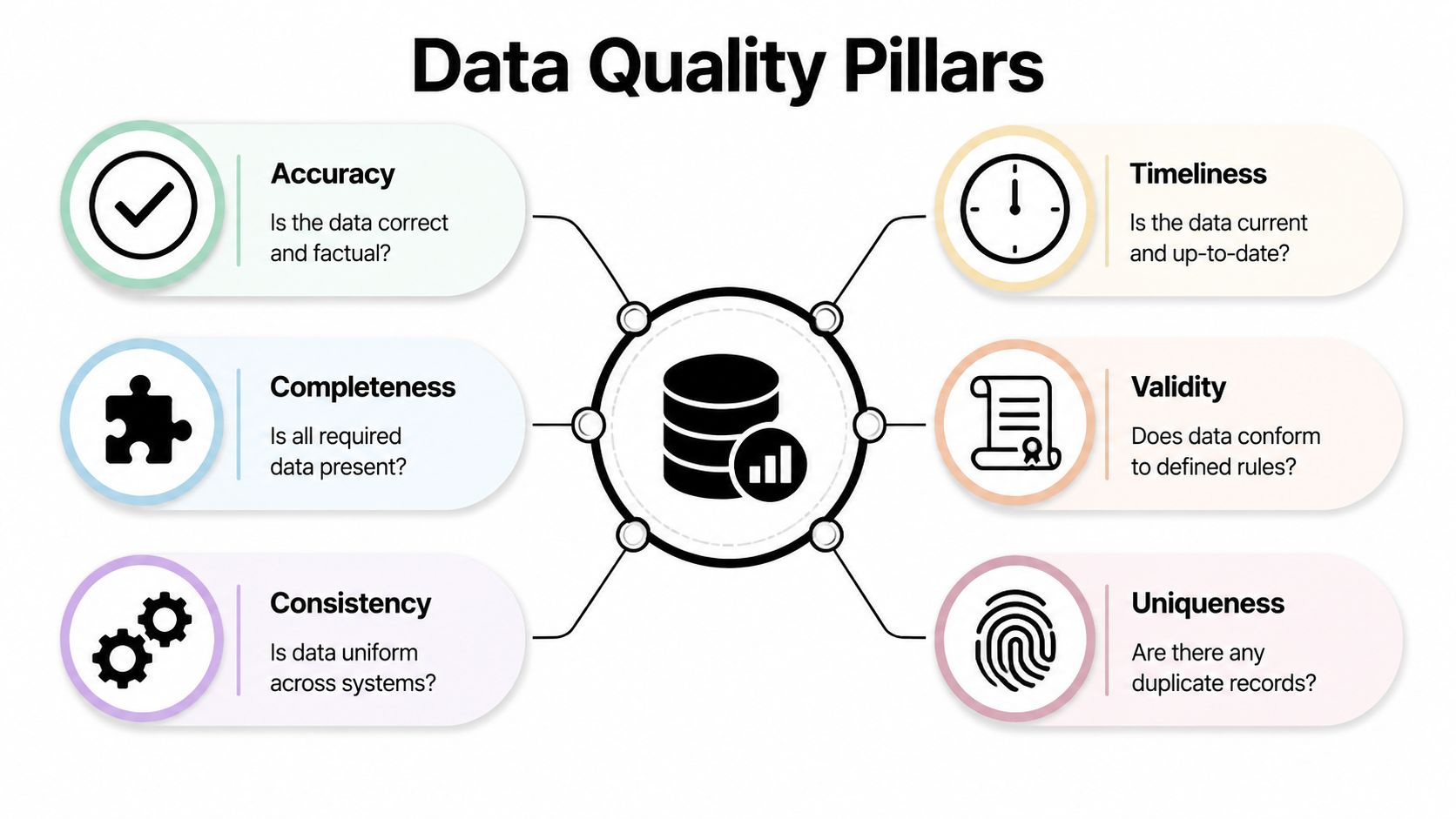
The six checks that actually matter
Marketing data sources should be evaluated against six practical pillars:
- Accuracy means the record is factually correct. If a title, company, or contact method is wrong, targeting breaks immediately.
- Completeness means the required fields exist. A lead without company size, region, or lifecycle stage can't flow cleanly into segmentation or routing.
- Consistency means the same field means the same thing across systems. “Enterprise” in your CRM can't mean one thing to sales and something else in paid audience exports.
- Timeliness means the record is current enough to act on. In B2B, that's critical because job changes, ownership changes, and account status changes affect outreach fast.
- Validity checks whether data conforms to the rules you defined. Country values, email formats, stage names, and account hierarchies need standards.
- Uniqueness means duplicate records aren't inflating activity, confusing attribution, or splitting account history across systems.
A lot of reporting problems are really quality problems in disguise. Marketers blame attribution when the root issue is duplicate accounts. SDRs blame messaging when the root issue is outdated roles.
What weak data quality does to pipeline
Weak quality creates operational drag at every stage:
| Quality failure | What the team sees | What's actually happening |
|---|---|---|
| Inaccurate records | Bounces, poor reply quality, wasted spend | The target isn't the person or company you thought it was |
| Missing fields | Weak segmentation, noisy scoring | The model is acting on partial context |
| Inconsistent values | Dashboards don't match | Systems are labeling the same thing differently |
| Stale data | Outreach lands badly | The buyer or account has changed since capture |
| Invalid formatting | Sync failures and broken automations | Rules weren't enforced at entry |
| Duplicate records | Inflated lead counts and confused ownership | One buyer exists in several places |
Mature teams also pull in offline and financial systems such as point-of-sale data, call-center logs, and cost or margin data because those sources create a stronger chain from campaign activity to revenue. Public sources like census data and search-trend datasets add context that helps teams separate campaign effects from broader demand shifts, as noted in Funnel's discussion of marketing data sources.
Bad data doesn't fail gracefully. It spreads through scoring, routing, forecasting, and compliance records all at once.
A useful audit habit is simple. Pick one high-value segment, inspect the records manually, then check how those records behave across CRM, automation, ad audiences, and reporting. You'll see quickly whether the source is reliable enough to scale.
The Modern Data Stack Integrating and Enriching Your Sources
Teams get into trouble when every platform becomes its own truth source. CRM says one thing, ad platforms say another, web analytics says something else, and finance has a fourth version of performance. At that point, the problem isn't a missing dashboard. It's architecture.
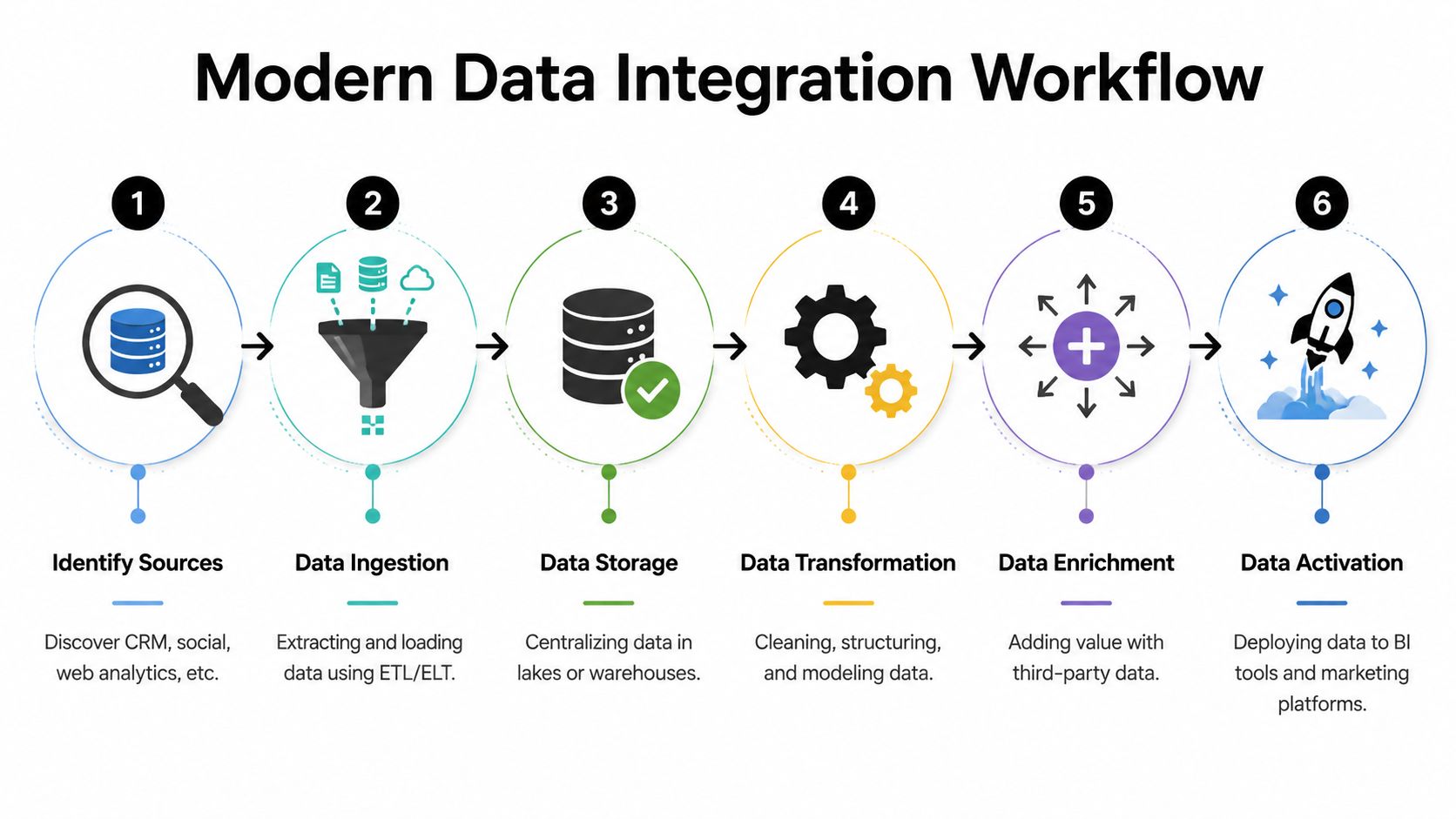
Why a warehouse changes decision quality
A strong marketing data architecture typically centers on a warehouse that unifies CRM, ad-platform, web analytics, and offline revenue data. The reason is straightforward. Siloed sources can't reliably attribute cross-channel performance or connect spend to downstream outcomes. ETL and ELT pipelines map source-specific fields into a shared model, which reduces reporting drift and helps teams build a single customer journey view across channels and devices. That operating model is outlined clearly in Improvado's guide to marketing data warehousing.
Marketers often confuse a dashboard with a data model. A dashboard shows outputs. A warehouse gives you governed inputs.
A practical stack usually includes:
- Source systems: CRM, ad accounts, analytics, email, support, finance
- Movement layer: ETL or ELT pipelines that ingest and standardize data
- Storage layer: warehouse or lakehouse
- Modeling layer: shared definitions for accounts, contacts, lifecycle, attribution, and revenue
- Activation layer: BI, automation, sales workflows, and audience syncs
If your team is still moving CSV exports between systems, you don't have an integration strategy. You have a manual exception process.
Where enrichment fits
Enrichment should happen after you have a stable backbone, not before. Otherwise you're appending data to records that still lack governance.
Used properly, enrichment fills in the fields your internal systems can't capture consistently on their own. That may include professional profile details, company attributes, verification status, or account-level context needed for routing and personalization. A tool such as marketing database software can help frame how those records are organized and maintained once they've been unified.
One example in this category is Icypeas, which can find, verify, and enrich professional contact records through API and web workflows. In a practical stack, a service like that fits between record capture and activation, especially when teams need to verify work emails, append company context, or turn sparse inbound records into usable account data.
A clean warehouse without enrichment stays incomplete. Enrichment without a clean warehouse stays chaotic.
The right order is simpler than people make it. Unify first. Standardize fields second. Enrich the gaps third. Activate only what your sales and marketing teams can trust.
Navigating Data Privacy and Compliance in 2026
Compliance isn't a legal sidebar anymore. It changes how marketing data sources are collected, stored, shared, enriched, and activated.

The practical rules marketers need
For marketers, the most useful way to think about GDPR and CCPA is through operating principles, not legal jargon.
- Consent and lawful basis matter: You need clarity on why data is being collected and how it will be used.
- Data minimization matters: Don't collect fields just because your form or provider can.
- Retention matters: If a record no longer serves a valid purpose, it shouldn't sit around forever.
- Access and deletion rights matter: Teams need a process for handling requests, not just a policy page.
- Vendor governance matters: If an outside provider touches your data, their practices become part of your risk surface.
For RevOps teams, privacy operations become very real. The question isn't only “Can we enrich this record?” It's also “Do we know where it came from, whether we should keep it, and how it is being used downstream?”
A plain-language privacy page can help internal teams understand what good stewardship looks like in practice. This example on How we protect your data is useful because it shows the kind of transparency buyers increasingly expect from software vendors.
Compliance changes how you choose sources
First-party data and external data don't create the same obligations in the same way. With first-party records, your team controls collection and retention more directly. With third-party or enrichment data, diligence shifts upstream. You need to understand provenance, permitted use, and how the provider handles updates and removals.
That's one reason source selection and compliance review should happen together, not sequentially.
Compliance works best when it's built into the workflow that creates and updates records, not added after the campaign is live.
A simple operating checklist helps:
- Review collection points: Forms, event imports, partner uploads, and manual list additions
- Limit unnecessary fields: If a field won't affect segmentation, routing, or service, question why it exists
- Track source lineage: Teams should know whether a record came from CRM capture, partner share, or enrichment
- Define usage boundaries: Sales, marketing, support, and product should not all inherit every field by default
Before you build policy into process, it helps to align the team on the practical side of modern data use:
The strongest compliance posture usually looks less dramatic than people expect. Fewer mystery fields. Better source documentation. Tighter retention logic. Clearer rules for enrichment and activation. That discipline protects the business and improves trust in the data itself.
Activating Data for Smarter Marketing Campaigns
The payoff from better marketing data sources isn't cleaner spreadsheets. It's sharper execution.
ABM gets sharper
A unified dataset makes account-based marketing less theatrical and more practical. Instead of targeting companies because they fit broad firmographic filters, teams can prioritize accounts where CRM history, website activity, partner signals, and enriched contact data align.
That changes execution fast. Marketing can build audiences around real account clusters. SDRs can see likely stakeholders earlier. Sales doesn't waste cycles on accounts that look big but show no buying motion.
Personalization and scoring stop being guesswork
Email personalization also improves when the team moves beyond first-name tokens. Good records support messaging based on role, segment, use case, and account context. That doesn't mean writing creepy outreach. It means writing relevant outreach.
Lead scoring gets more useful for the same reason. A score built only on page views and email clicks tends to overvalue activity. A score that also considers CRM stage, account fit, verified contact quality, and meaningful engagement signals does a better job of helping sales focus.
Three practical activation patterns show up again and again:
- ABM targeting: Build target account lists from first-party fit signals, then enrich missing stakeholder data so outreach maps to the buying group.
- Email personalization: Use verified role and company context to adapt messaging, offers, and follow-up paths.
- Lead prioritization: Combine fit, engagement, and data confidence to rank records for SDR action.
If your team is evaluating where external collection and enrichment fit inside that activation layer, this guide on legal scraping considerations is worth reviewing because source legality and usage boundaries affect campaign risk, not just data ops.
The best campaigns don't use more data. They use the right data, in the right sequence, with clear ownership.
When that happens, pipeline quality improves in a very practical way. Fewer bad-fit leads get routed. More qualified accounts receive relevant touches. Sales gets context instead of raw names. Marketing can finally judge performance by business movement, not just channel activity.
If your team needs to turn sparse records into usable B2B pipeline data, Icypeas is one option to evaluate. It helps sales, marketing, and RevOps teams find, verify, and enrich professional contact and company data so CRM records, outbound workflows, and inbound handoffs are easier to trust.





























































.png)



.webp)