.avif)
What Is Open Source Intelligence: A 2026 Guide


.avif)
Open source intelligence is the structured process of gathering and analyzing publicly available information to produce actionable business insight, not random web searching. With more than 400 million terabytes of data generated every day worldwide, OSINT has become a practical way for sales and marketing teams to turn scattered public signals into usable lead, account, and market context.
A familiar B2B problem starts like this: a lead fills out a form with a work email, no phone number, a vague company name, and a job title that might be outdated. Your SDR can send a generic sequence and hope for the best, or your team can use public information to identify the company, verify the person's role, understand what the business does, and tailor outreach around real context.
That second path is what OSINT looks like in business.
The term still carries spy-movie baggage. People hear “intelligence” and assume surveillance, scraping, or something legally risky. In practice, good OSINT for revenue teams is much less dramatic and much more operational. It means working from publicly available, legally accessible information, then filtering, validating, and connecting it so a sales or marketing team can act on it.
For B2B teams, that often means account research, lead enrichment, contact verification, territory mapping, competitive monitoring, and CRM hygiene. The value isn't that the data is public. The value is that someone can turn public data into a clear answer to a commercial question.
Table of Contents
- Raw data is abundant. Intelligence is selective
- The intelligence step creates value
- What works and what doesn't
An Introduction to Open Source Intelligence
Open source intelligence, usually shortened to OSINT, means collecting and analyzing information from open sources to produce actionable intelligence. In business terms, that means using public websites, company pages, social profiles, public records, media coverage, and similar sources to answer a specific question.
The specific question matters.
If your team is gathering whatever it can find, that's research without direction. If your team is asking, “Who are the likely decision-makers at this account?” or “Is this inbound lead a real buyer at a real company?” and then assembling public evidence to answer it, that's much closer to real OSINT.
Researchers cited by the American Public University System estimate that approximately 80% to 90% of all intelligence comes from open sources in intelligence work, which helps explain why the same discipline has become so useful in commercial teams (American Public University System on why open-source collection is critical).
Why B2B teams care
Sales and marketing teams don't need covert methods. They need better context.
A rep wants to know whether a prospect recently changed roles. A demand gen manager wants to enrich a list of sign-ups before routing them. A rev ops team wants to clean stale CRM records without relying on guesswork. OSINT helps with all three because it works from signals buyers and companies have already made public.
Practical rule: OSINT starts with a business question, not a browser tab.
What OSINT is not
It isn't just typing a name into Google. It isn't copying data from one profile and calling that “intelligence.” And it isn't a license to ignore privacy, consent, or compliance.
Done well, OSINT is disciplined. It asks what data is relevant, where it comes from, whether it's current, and how confident you should be before using it in an outbound sequence, lead score, or routing rule.
That's why the strongest OSINT workflows look less like hacking and more like good data operations.
Distinguishing Raw Data from Actionable Intelligence
A lot of confusion around what is open source intelligence comes from treating raw public data and finished intelligence as if they were the same thing. They're not.
One can compare it to cooking. Raw ingredients in a kitchen aren't dinner. Flour, tomatoes, garlic, and olive oil only become a meal after someone selects what matters, combines it correctly, and prepares it for a purpose. Public data works the same way. A company page, a founder interview, a job listing, and a professional profile are just ingredients until someone uses them to answer a business question.
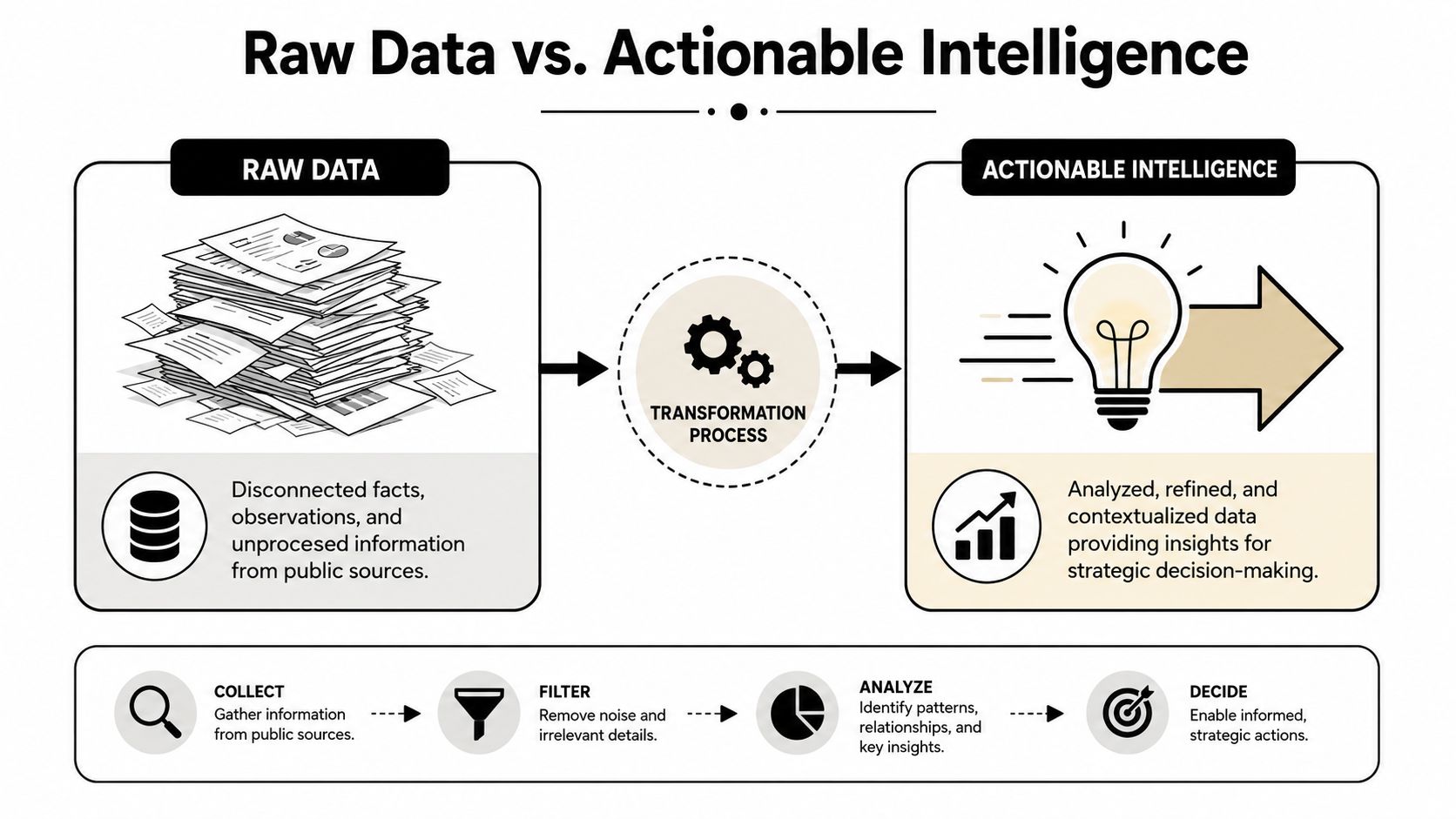
Raw data is abundant. Intelligence is selective
Many teams go wrong by assuming more collection automatically means better insight. In practice, broad collection often creates noise, duplicates, stale records, and false confidence.
Imperva makes the distinction directly: raw public data is not yet intelligence until it has been filtered for relevance and assembled to answer a specific question, and it warns against maximizing collection volume when targeted retrieval would do the job better (Imperva's explanation of OSINT and focused collection).
A rep researching a target account doesn't need every public mention of the company. They need the few signals that help them act. For example:
- Recent hiring activity can suggest expansion, new budgets, or team buildout.
- Leadership changes can signal a new buying process.
- Product pages and integrations can reveal likely tech stack fit.
- Press releases can indicate partnerships, launches, or geographic growth.
The intelligence step creates value
The source itself usually isn't the advantage. The advantage comes from interpretation.
Here's the difference in practice:
| Situation | Raw data | Actionable intelligence |
|---|---|---|
| Inbound lead | Email address and company field | Verified company, probable role, seniority, and account fit |
| Target account research | Website, news mentions, employee pages | Clear outreach angle tied to recent business activity |
| CRM cleanup | Contact record with old title | Evidence that the person changed role or left the company |
Public information becomes useful when it answers, “What should the team do next?”
What works and what doesn't
What works is a narrow brief, a small set of trustworthy source types, and a decision to make. What doesn't work is opening twenty tabs, copying fragments into a spreadsheet, and treating accumulation as analysis.
That's the practical line. Open data is what exists. Open source intelligence is what your team can use.
The OSINT Process for Business Intelligence
The reason OSINT works in business is that it follows a repeatable process. Without process, teams collect trivia. With process, they produce usable account and contact intelligence.
The scale of the public data environment makes that structure necessary. More than 400 million terabytes of data are generated every day worldwide, and the OSINT market was USD 12.7 billion in 2025 with a projection of USD 133.6 billion by 2035, showing how quickly demand for structured open-source analysis is growing (GDIT on OSINT data volumes and market growth).
A simple business workflow usually follows five stages.
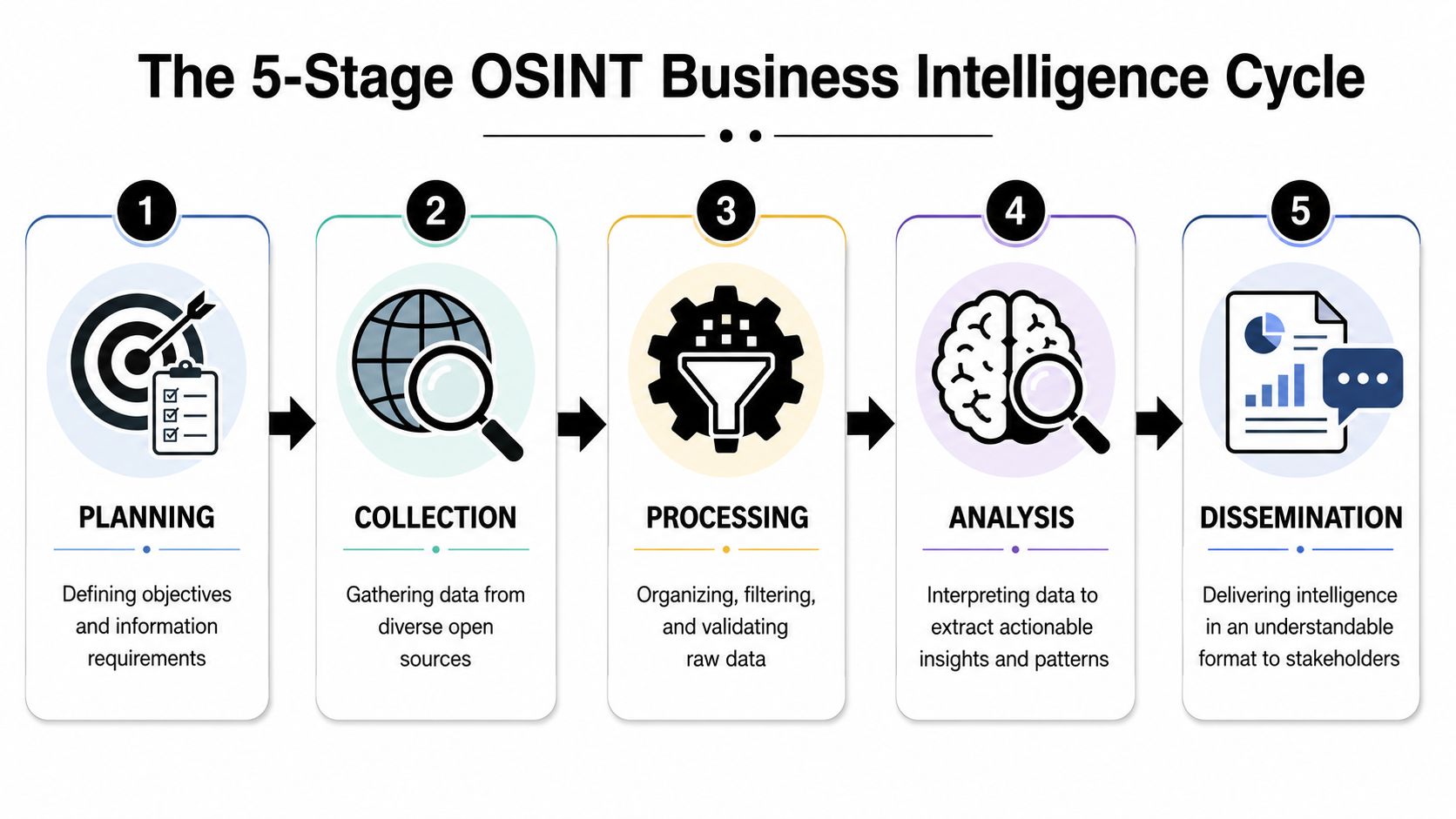
Planning
Start with a concrete requirement. “Find fintech contacts” is too broad. “Identify heads of partnerships at European fintech companies hiring for compliance and payment operations” is specific enough to guide collection.
Good planning also sets boundaries. Decide which geographies, source types, and freshness standards matter before you start. Otherwise, the team drifts into data hoarding.
Collection
Collection means gathering relevant public information from the source categories that fit the brief. For B2B teams, that may include company websites, professional profiles, job pages, public filings, media coverage, and business directories.
This is also where teams decide whether to do the work manually or use a provider or API. A technical walkthrough of how Icypeas finds contact data is useful here because it shows the practical difference between finding a single record and building a repeatable enrichment workflow.
Processing
Raw collection is messy. Records come in different formats. Titles vary. Companies appear under multiple names. Dates are inconsistent. Some data points conflict.
Processing cleans that up. Teams normalize company names, standardize titles, remove duplicates, and discard records that don't meet the brief. This stage often gets ignored because it isn't glamorous, but weak processing ruins later analysis.
A useful habit is to keep a confidence note beside key fields. If a role appears on three recent public signals, confidence is higher than if it appears on one old page with no corroboration.
Before moving on, it helps to see the lifecycle in action:
Analysis
Analysis is where the dots get connected. One signal rarely matters on its own. Patterns matter.
A single hiring page may not tell you much. A hiring page plus a new product launch plus a partner announcement starts to tell a story. For a seller, that story might be “this account is building a new function and may need tooling, services, or data.”
Dissemination
Intelligence only matters if the right team can use it. That means packaging findings in the format the business uses. CRM fields, routing logic, account notes, enrichment outputs, and prospecting lists are more useful than a research memo no one opens.
The final test for OSINT isn't whether it was thorough. It's whether a seller, marketer, or operator can act on it today.
Common Public Sources for B2B OSINT
For most revenue teams, the phrase “public data” is too vague to be useful. Better OSINT starts with a clear mental map of source types and what each one can realistically tell you.
That matters because open sources have long supplied the majority of intelligence work. Researchers cited by the American Public University System estimate that approximately 80% to 90% of all intelligence comes from open sources. In B2B, the same logic holds. The signal is often already public if you know where to look and how to combine it (American Public University System on open sources in intelligence work).
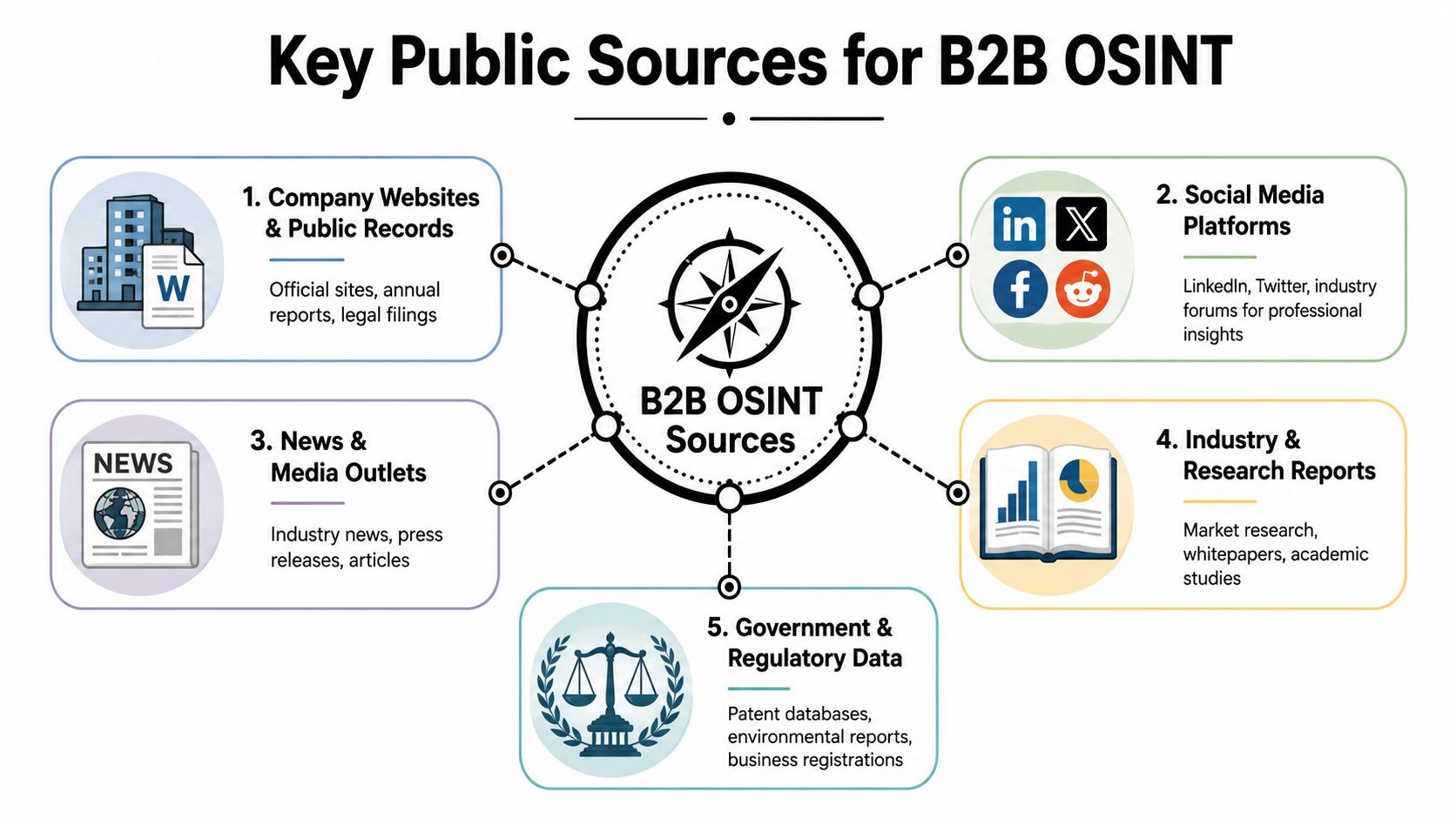
Five source groups that matter most
Company websites and public records
Official sites often give the cleanest first-party context: products, leadership, office locations, partner pages, careers pages, and press rooms. Public business records can help confirm legal entity names and registration details.Professional and social platforms
These are useful for role validation, team structure, professional history, and topic interest. The strongest use isn't copying a profile. It's cross-checking whether a person, function, and company relationship still appears current.News and media outlets
Media coverage helps with timing. Recent funding, leadership announcements, launches, acquisitions, or geographic expansion can make outreach more relevant.Government and regulatory data
Depending on the market, this can reveal contract awards, registrations, regulatory events, or official disclosures that matter for account qualification.Academic and technical publications
These are especially useful in technical industries. They can surface researchers, domain specialists, and emerging areas of commercial activity.
Matching the source to the question
Different questions require different sources. If you want buying context, start with company pages and news. If you want org structure clues, professional profiles and job pages are often more useful. If you want market signals, combine media, reports, and public records.
A practical starting point for teams building their sourcing stack is this overview of marketing data sources, which helps separate first-party, public, and external inputs by use case.
A common mistake is using the same sources for every task. Source selection should change with the question.
What experienced teams avoid
They avoid overvaluing a single source, especially when that source is outdated or self-reported. They also avoid treating source availability as source quality. If a source is easy to access but hard to verify, it shouldn't carry much weight in a business decision.
How Sales and Marketing Teams Use OSINT
The fastest way to understand what is open source intelligence is to look at how teams use it. In B2B revenue work, the pattern is usually the same: start with incomplete information, use public signals to improve it, then push the result into outreach, routing, or CRM workflows.
Prospecting with account context
Before OSINT, a rep may have nothing more than a company name on a target list.
After OSINT, that same rep may know which product line the company is emphasizing, which regions it's hiring in, whether it recently announced a partnership, and which leaders appear closest to the problem your offer solves. That changes the outreach from generic to relevant.
Public professional signals are particularly valuable. Teams working on optimizing sales team's LinkedIn outreach often focus on sequencing and messaging, but the inputs matter just as much. Better public context usually produces better outreach angles.
Before
- Target account list only with little explanation of why each company belongs there
- One generic sequence sent to multiple titles
- Weak personalization based on industry clichés
After
- Role-aware prospect list with likely function owners
- Account notes tied to real public signals
- Outreach copy aligned to actual initiatives or changes
Enriching inbound leads
Inbound forms are messy by nature. People shorten company names, use aliases, skip fields, or submit with only an email address. Marketing automation can route that lead, but routing without context creates wasted follow-up.
OSINT helps fill the gaps. A business can use a work email domain, company page, role clues, and other public indicators to identify who the lead likely is in the organization and whether the account fits your ICP.
That doesn't mean collecting everything available. It means enriching the few fields that improve the next action. For an SDR, that may be title, seniority, department, and company profile. For marketing ops, it may be account match, segmentation, and geographic compliance handling.
Verifying and cleaning contact data
The least glamorous use case is often the most valuable. Public data is useful not just for finding contacts, but for deciding whether your existing records still make sense.
A title may have changed. A person may have moved companies. A business may have rebranded. A domain may still accept mail while the named employee is no longer there. OSINT gives ops teams a way to check whether public evidence still supports the record in the CRM.
Clean contact data usually comes from repeated verification, not one-time enrichment.
A good workflow here uses public confirmation signals conservatively. If the record looks stale, flag it for review or revalidation instead of automatically trusting old CRM data. That approach reduces bad personalization and lowers the odds of sending the wrong message to the wrong person.
Navigating the Legal and Ethical Boundaries of OSINT
The biggest objection many teams have to OSINT isn't whether it works. It's whether they can use it without stepping into legal or reputational trouble.
That concern is healthy.
OSINT includes publicly available, legally accessible information, but using that information still requires ethical and legal judgment. A neutral overview of the field also notes that many explainers gloss over modern boundaries such as GDPR, CCPA, and the question of whether cached or aggregated public data should still be treated as “open” in practice (Wikipedia's overview of open-source intelligence and compliance boundaries).
The line that matters
For business teams, the safest practical test is simple: can you clearly explain why the source is public, why the use is relevant, and how the data supports a legitimate business purpose?
If the answer is fuzzy, stop.
That line becomes important in people research. For example, image-based identification can raise obvious privacy concerns even when a technical path exists. If your team is exploring that territory, it helps to understand the mechanics and risks before touching any workflow. A technical explainer like AI Image Detector's guide on identification is useful as background because it shows how easily identification moves from curiosity into sensitive processing.
What ethical OSINT looks like in practice
Use relevant data only
If a data point doesn't help answer the commercial question, don't collect it.Favor legitimate public sources
Prioritize information that is openly published and reasonably accessible, not obtained through deceptive access.Keep records of provenance
Teams should know where a data point came from and when it was observed.Respect jurisdictional rules
Public availability doesn't override data protection obligations.
What usually goes wrong
Problems usually start when teams confuse “technically accessible” with “appropriate to use.” Another common failure is over-automation without human review. A workflow can ingest public signals at scale and still produce inappropriate outputs if no one checks purpose, relevance, and currentness.
Ethical OSINT is less about how much you can collect and more about whether you should use it at all.
For revenue teams, compliance isn't a drag on growth. It's what makes growth durable.
Evaluating OSINT Tools and APIs for Your Business
Once a team understands the method, the next question is operational: which tools can support it?
The important thing to remember is that an OSINT tool isn't just a search box. Operationally, OSINT is a pipeline that ingests open sources, normalizes them, and applies correlation to surface hidden relationships. The intelligence value comes from linkage at scale, not from the source itself. Cognyte describes this as building algorithms that associate disparate data points so analysts can extract “entire concepts” from open data (Cognyte on the OSINT pipeline and correlation).
A practical evaluation checklist
If you're comparing vendors, APIs, or internal build options, use criteria that map to your workflow.
| Criteria | What to check |
|---|---|
| Data relevance | Does the tool fit B2B prospecting, enrichment, verification, or another use case entirely? |
| Freshness | Can the provider explain how often records are refreshed or revalidated? |
| Compliance posture | Can the team explain source handling, legal boundaries, and processing approach? |
| Integration | Is there an API or export path that fits your CRM and automation stack? |
| Explainability | Can users trace why a record or suggested match exists? |
Tool fit matters more than feature volume
A cybersecurity OSINT platform and a B2B enrichment API may both work with open sources, but they solve different problems. Don't buy depth where you need workflow fit.
If you're surveying categories before selecting a stack, this roundup of competitive intelligence platforms is a useful comparison point because it shows how different products serve different intelligence jobs.
For teams that need enrichment and contact workflows rather than broad investigations, it also helps to understand the API layer itself. This guide on what a data API is is a practical starting point for evaluating how OSINT outputs get embedded into applications, forms, and CRM processes.
The strongest buying decision usually comes from one simple question: will this tool help your team answer a real business question faster, more reliably, and within your compliance rules?
If your team wants to use OSINT for B2B enrichment, verification, or contact discovery, Icypeas is one option built around that workflow. It provides business contact enrichment and lookup capabilities through web tools and an API, with a focus on publicly available data, verification, and compliance-oriented use in sales and marketing operations.










































































.png)



.webp)