.avif)
The Data Quality Manager: An Essential Guide for 2026


.avif)
Your CRM says the quarter looks healthy. Marketing says lead volume is up. Sales says half the “hot” accounts are junk, and the SDR team is wasting time on duplicates, missing fields, and contacts who left months ago. Product is pushing activation campaigns with incomplete user profiles. Finance wants a forecast it can trust, but the inputs keep changing depending on which dashboard someone opened.
That's the moment when companies realize bad data isn't a reporting inconvenience. It's a revenue problem.
A good Data Quality Manager doesn't sit in the background cleaning spreadsheets. They protect pipeline, improve campaign efficiency, reduce friction between teams, and make the operating system of growth work the way leadership thinks it already does. When the role is done well, sales trusts the CRM, marketing trusts segmentation, product trusts user data, and leadership trusts the numbers in the board deck.
Table of Contents
- Data profiling and auditing
- Data cleansing and deduplication
- Data governance and policy creation
- Performance monitoring and reporting
- Technical skills that matter in the real world
- Business and soft skills that separate operators from custodians
- Hiring manager checklist
The Hidden Costs of Bad Data
A familiar failure looks like this. Marketing launches a targeted campaign to a carefully segmented list. Creative is solid, timing is right, and the offer fits the audience. Then the results come back weak because the list was packed with stale contacts, missing firmographic fields, and duplicate records that inflated expected reach.
Sales sees the same problem from a different angle. Reps open an account and find three versions of the same company, each with partial activity history. One record has the owner, another has the opportunity, and a third has the latest contact. Forecast calls start drifting because nobody is sure which record reflects reality.
This is why bad data keeps showing up as “team inefficiency” when it's really lost pipeline. People don't just waste time. They make weaker decisions with more confidence than they should have.
Bad data rarely announces itself as a data problem. It shows up as missed follow-up, noisy attribution, poor routing, and arguments over whose numbers are right.
The damage spreads subtly across the stack:
- Marketing spends against the wrong audience: Segments break when job titles, company data, or lifecycle stages are inconsistent. For teams managing large marketing databases, that usually means wasted sends, messy attribution, and weaker campaign planning.
- Sales prioritizes the wrong accounts: Duplicate records distort account scoring, ownership rules, and activity history.
- Product teams misread behavior: Incomplete or inconsistent user data makes onboarding and lifecycle messaging less relevant.
- Leadership loses confidence in reporting: Once teams start questioning source data, every dashboard becomes a debate.
A company can tolerate imperfect data for a while. It can't scale on it. Once volume increases, every broken field mapping and every sloppy manual import starts compounding. The cost isn't just cleanup work later. It's lower conversion quality now, slower execution this quarter, and less trust in every decision that depends on customer data.
What Is a Data Quality Manager
A Data Quality Manager is the person who makes sure the business can rely on its data the same way operations relies on inventory accuracy or finance relies on controlled books. The job isn't to “own reports.” It's to own trust in the underlying records that power those reports.
The simplest analogy is a data supply chain foreman. Raw materials enter from forms, product events, CSV imports, enrichment vendors, SDR research, CRM edits, and syncs between tools. If nobody inspects, standardizes, and controls that flow, the output becomes inconsistent. Sales gets one version of the customer, marketing gets another, and product gets a third.
According to Société Générale's role description, Data Quality Management is the process of managing data to enable informed decision-making while mitigating risks, and a Data Quality Manager owns that process. The same source notes that Data Quality Analysts spend approximately 40% of their time on monitoring, validation, profiling, and identifying inconsistencies within governance frameworks, which tells you how much day-to-day operational effort quality requires in practice through this Data Quality Manager overview from Société Générale.
Architect of trust
The best Data Quality Managers work at the intersection of systems, process, and accountability. They define what “good” looks like, where data enters the business, which fields are mandatory, how duplicates are handled, who fixes failures, and how issues get prevented instead of repeatedly patched.
That's why this role belongs much closer to RevOps, Sales Ops, Marketing Ops, and data governance than many org charts suggest. If your CRM drives pipeline review, lead scoring, routing, lifecycle automation, and territory decisions, quality control is a growth function.
A strong manager in this role usually owns or influences work such as:
- Standards: Defining completeness, accuracy, consistency, and validity rules
- Entry controls: Applying validation logic where data first enters the system
- Cross-system consistency: Keeping CRM, marketing automation, and related systems aligned
- Exception handling: Investigating failures and assigning ownership
- Enablement: Training teams so they stop reintroducing the same errors
Why the role is strategic
Most companies only feel the importance of this role after trust breaks. They hire after forecasting slips, campaign performance becomes noisy, or a migration exposes years of unmanaged duplication. That's reactive.
The more strategic view is simpler. A Data Quality Manager protects the inputs to revenue operations. They make sure leads route correctly, account views stay unified, segmentation rules stay usable, and leadership can act on reports without asking whether the data is clean enough to believe.
Core Responsibilities and Daily Tasks
A Data Quality Manager's calendar isn't filled with abstract governance meetings. The work is operational, repetitive in the right places, and strongly tied to business outcomes. Good managers treat quality like a control system, not a one-time cleanup project.
Monte Carlo's practical framework describes modern DQM as a six-step discipline: baseline current quality, align the organization, implement broad monitoring, optimize incident resolution, create custom monitors, and focus on prevention. It also highlights two often-overlooked parts of the role: educating functional groups on data usage and clearly defining accountability through this modern data quality management guide.
Data profiling and auditing
The work starts here. Before anyone fixes data, they need to understand how it's failing.
Daily and weekly tasks often include:
- Querying for gaps: Running SQL checks for null values, invalid formats, orphaned records, and suspicious spikes in field usage
- Comparing systems: Reviewing CRM, MAP, billing, and product data for mismatches in key identifiers
- Tracing entry points: Finding where bad values originate, such as forms, integrations, manual imports, or rep edits
- Documenting patterns: Separating isolated mistakes from recurring failure modes
A useful profile doesn't just say “data is messy.” It tells you which fields break routing, segmentation, attribution, or reporting first.
Data cleansing and deduplication
Cleanup is the visible part of the role, but it's only valuable when tied to business logic. Merging duplicates without deciding survivorship rules creates fresh problems. Standardizing titles without understanding territory assignment can break workflows downstream.
Common tasks include:
- Merging duplicate accounts and contacts: Especially where ownership, opportunity history, and activity logs overlap
- Standardizing values: Normalizing country names, industry values, job functions, lifecycle stages, and source labels
- Repairing key fields: Correcting emails, domains, phone formats, and account hierarchies
- Setting survivorship logic: Determining which source wins when fields conflict
Practical rule: If a cleanup task can't explain how it improves routing, reporting, segmentation, or forecasting, it's probably cosmetic.
Data governance and policy creation
What separates experienced operators from spreadsheet fixers is the work of a Data Quality Manager, who creates rules that stop teams from recreating the same mess next month.
That usually means:
- Defining standards: What counts as complete, accurate, and usable for each object and field
- Clarifying ownership: Who is responsible for fixing contact data, account mapping, lifecycle stages, or enrichment failures
- Writing playbooks: How imports happen, how new picklists are approved, how dedupe exceptions are handled
- Training teams: Showing SDRs, marketers, CSMs, and ops users how their actions affect downstream systems
The point isn't bureaucracy. It's consistency. Without policy, every team invents its own version of the customer record.
Performance monitoring and reporting
A mature quality function measures health continuously. It doesn't wait until a campaign underperforms or a forecast misses.
Typical outputs include:
- Dashboards: Tracking completeness, duplicate trends, validation failures, enrichment coverage, and freshness
- Alerting: Flagging integration failures, unusual field drift, or sudden drops in usable records
- Incident reviews: Explaining what broke, who owned the fix, and how recurrence will be prevented
- Business reporting: Translating quality issues into operational impact for sales, marketing, and leadership
The daily rhythm often alternates between detective work and prevention work. One hour might be spent investigating why lead routing failed. The next might go into revising form validation, updating field requirements, or coaching a team that keeps importing bad CSVs.
That's what the role really is. It's part analyst, part systems owner, part process architect, and part internal operator who keeps the company from making expensive decisions on unreliable inputs.
Essential Skills and How to Hire One
Most hiring teams write this role too narrowly. They ask for someone who can clean records, run SQL, and manage dashboards. That's not enough. The person you want is closer to a revenue systems operator with strong quality instincts and the credibility to challenge bad process.
In New York, the average annual salary for a Data Quality Manager is $106,280, with most professionals earning between $72,200 and $137,300, and broader U.S. data places the average at $110,539 per year. The role typically calls for 5+ years of related experience, a technical degree is common, and employers often expect proficiency in SQL, Python, Informatica, Talend, Tableau, Power BI, and Excel, according to this New York Data Quality Manager salary and role snapshot.

Technical skills that matter in the real world
The technical side matters, but only in service of business control.
Look for candidates who can handle:
- SQL with purpose: Not just querying tables, but isolating root causes behind missing values, broken joins, and duplicate logic
- Python or automation fluency: Useful for repeatable checks, transformations, and exception handling
- Tool familiarity: Experience with Informatica, Talend, Tableau, Power BI, and Excel is practical because quality work lives across enterprise stacks
- CRM and MAP literacy: They should understand objects, field dependencies, lead routing, sync behavior, and lifecycle automation
- Privacy-aware operations: Data quality and compliance intersect often, especially when records move across systems, so familiarity with workflows around data privacy automation is valuable
A candidate who only knows data tooling but can't explain how bad fields break pipeline won't be effective.
The video below gives a useful baseline on the broader discipline behind the role.
Business and soft skills that separate operators from custodians
This is the part many teams miss. Data quality work creates friction by design. Good managers say no to bad imports, challenge inconsistent definitions, and force teams to pick owners when nobody wants the cleanup ticket.
The strongest candidates usually show:
- Cross-functional communication: They can explain a validation rule to a sales manager and an engineer without losing either audience
- Stakeholder management: They know how to negotiate standards when marketing wants flexibility and sales wants speed
- Process thinking: They fix upstream causes instead of endlessly cleaning downstream outputs
- Attention to detail: Small field-level issues often signal larger systemic problems
- Commercial judgment: They understand which data issues threaten revenue first and prioritize accordingly
A strong hire doesn't say, “I cleaned the CRM.” They say, “I fixed the workflows and ownership model that kept dirtying it.”
Hiring manager checklist
Hiring Manager Checklist
- Ask for root-cause examples: “Tell me about a recurring data issue you stopped at the source.”
- Test business reasoning: “Which is more urgent, duplicate accounts or incomplete lifecycle stages, and why?”
- Probe systems thinking: “How would you prevent bad data entering from forms, imports, and integrations at the same time?”
- Listen for trade-offs: Strong candidates won't promise perfect data. They'll talk about prioritization, governance, and operational constraints.
- Look for operator language: Green flags include ownership models, validation rules, monitoring, prevention, and incident response.
- Check change management skills: Ask how they got sales, marketing, or product teams to follow standards they initially resisted.
If you're hiring for this role, don't optimize for the neatest résumé. Optimize for someone who can make messy systems more trustworthy without slowing the business to a crawl.
The Data Quality Management Workflow in Practice
The most effective teams run data quality as a workflow, not a cleanup sprint. The sequence matters because each stage reduces a different kind of risk. Skip one, and the next stage gets noisier, slower, or less reliable.
A practical five-stage model works well for RevOps and growth environments because it mirrors how revenue data moves through the business.
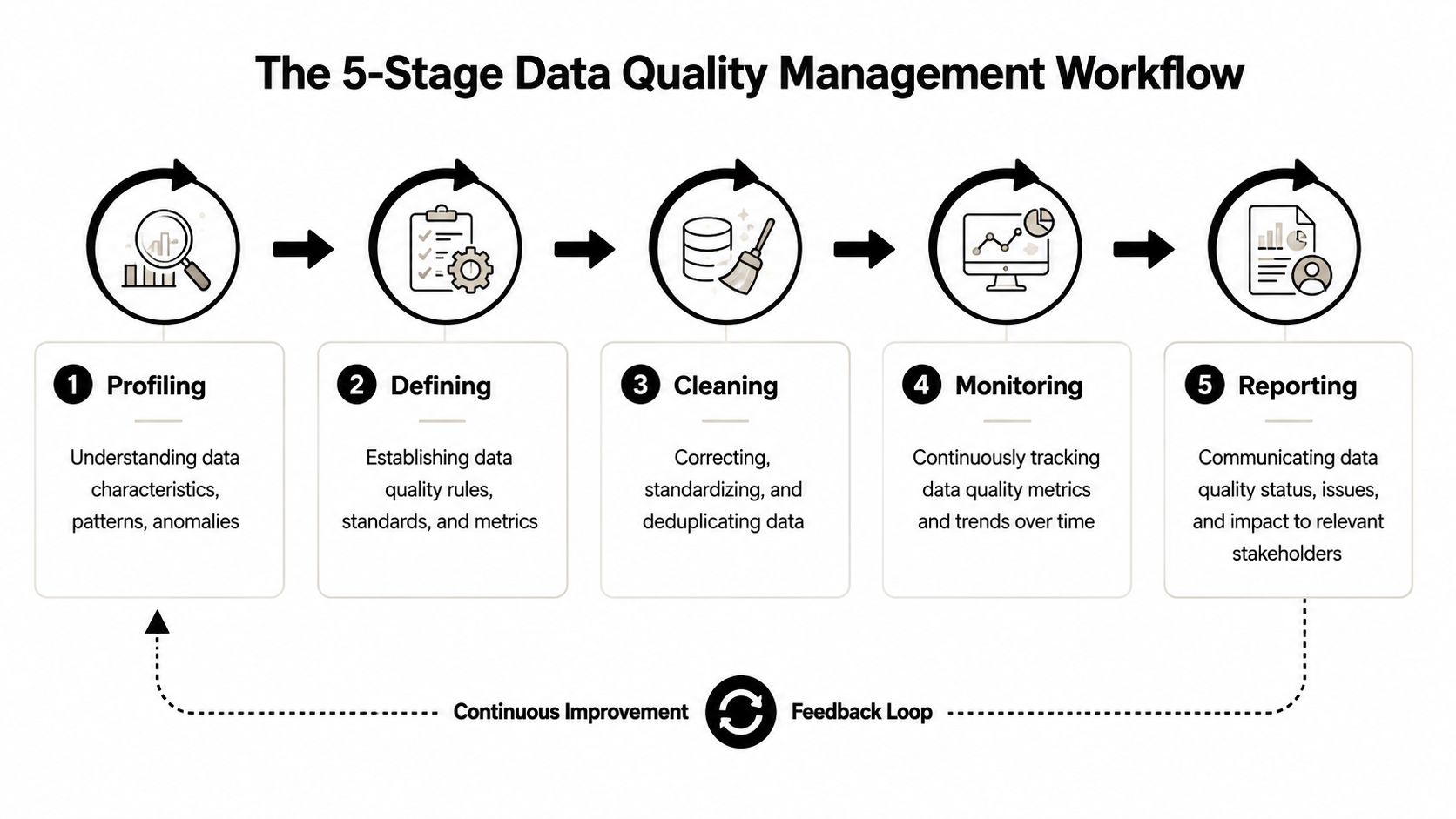
Profiling
This is the diagnostic pass. You inspect what exists before deciding what to fix.
A Data Quality Manager looks for field completeness, format consistency, stale records, duplicate patterns, source-by-source variation, and broken joins between systems. In a B2B environment, this often surfaces a hidden truth: most data issues aren't random. They cluster around a few sources, teams, or workflows.
Cleansing
Once the failure modes are visible, you correct what's broken. That includes standardization, formatting repairs, field normalization, and deduplication.
The trap here is treating cleansing as success by itself. It isn't. Cleansing buys time. Unless the manager also changes validation rules, import controls, and sync logic, the same issues return. When duplicate control is part of the workflow, it helps to document exactly how records are matched and merged, which is why teams often align this work with guides on detecting and removing duplicates in operational systems.
Enrichment
Clean data can still be thin. A lead with only a first name and email might be valid, but it isn't very useful for routing, segmentation, or prioritization.
Enrichment fills in the missing context. Titles, company details, firmographics, ownership clues, and standardized account attributes make the record actionable. This matters a lot in B2B pipeline management, where segmentation quality drives campaign performance and account targeting. Teams refining that layer often benefit from broader thinking around CRM strategies for B2B marketing, because data quality decisions shape how those strategies perform in practice.
Verification
Verification answers a different question from cleansing. Cleansing asks, “Is the record formatted correctly?” Verification asks, “Can we trust it?”
That means checking whether contact details are still valid, whether company references are current, whether key fields make sense together, and whether records meet the standards required for activation. This is the stage that protects sender reputation, routing confidence, and campaign execution.
Clean isn't the same as trustworthy. A perfectly formatted bad email is still bad data.
Monitoring
Monitoring turns quality from project work into operational discipline. It tracks whether the system is staying healthy after fixes go live.
A good monitoring layer watches for:
- Field drift: Required values suddenly go missing more often
- Source degradation: One form, sync, or import starts producing lower-quality records
- Freshness issues: Records age out and lose usefulness
- Process failures: Validation rules get bypassed or ownership queues stall
Through monitoring, the role becomes sustainable. Without monitoring, companies keep rediscovering old problems. With monitoring, they catch degradation before it reaches pipeline reviews, campaign launches, and executive reporting.
Building the Modern Data Quality Tech Stack
A Data Quality Manager needs more than discipline. They need a stack that supports control at input, repair in motion, and trust at activation. The right setup usually combines governance, transformation, monitoring, enrichment, and verification. The wrong setup is a patchwork of exports, one-off scripts, and “we'll fix it in the CRM later.”
According to ZoomInfo's description of the role, the primary goal is to keep CRM and marketing automation systems at high data hygiene, and the broader U.S. average salary of $110,539 reflects how central that responsibility has become in operational environments through this overview of data quality manager responsibilities.
Systems for control and structure
Start with systems that prevent bad data from spreading.
That usually includes:
- CRM controls: Required fields, validation logic, dedupe rules, and object relationships in systems like Salesforce or HubSpot
- ETL or integration layers: Informatica, Talend, or similar tooling to standardize and map values between systems
- BI and dashboards: Tableau, Power BI, or Looker to expose trends, exceptions, and operational risk
- Data access layers: APIs and middleware that let teams inspect and govern movement between tools. If your operation depends on connected enrichment and sync workflows, it helps to understand what a data API is and how it fits modern systems
These tools create structure, but structure alone doesn't create trustworthy records.
Systems for enrichment and trust
Many stacks fall short. A company can have excellent validation rules and still run poor segmentation if records are missing business-critical context. It can have strong dashboards and still damage campaign performance if contact data isn't verified before activation.
Modern stacks usually need dedicated capabilities for:
- Data enrichment: Filling in professional, firmographic, or account-level gaps that make records usable
- Email verification: Confirming deliverability before sales or marketing touches a contact
- Entity resolution: Matching fragmented records across systems into one usable customer view
- Ongoing refresh: Keeping records current as people change roles, companies evolve, and fields decay over time
For RevOps teams, quality transitions from a defensive measure to an enabler of growth. Better enriched and verified data improves routing, targeting, personalization, and outbound execution.
What works and what usually fails
What works is boring in the best way. Controlled entry points. Clear field ownership. Repeatable enrichment rules. Measured verification before activation. Monitoring tied to business workflows.
What fails is also predictable:
- Spreadsheet cleanups without policy changes
- One-time CRM projects with no ongoing monitoring
- Buying more data without fixing governance
- Letting every team create fields and picklists freely
- Treating verification as optional before campaigns launch
A healthy stack doesn't aim for theoretical perfection. It supports the practical goal of reliable customer and prospect data across the systems that drive pipeline, automation, and planning.
Sample Dashboards for Key Stakeholders
The output of a Data Quality Manager shouldn't stop at issue logs. A key indicator is whether different teams can see data health in a way that improves decisions. Good dashboards translate technical quality into operational meaning.
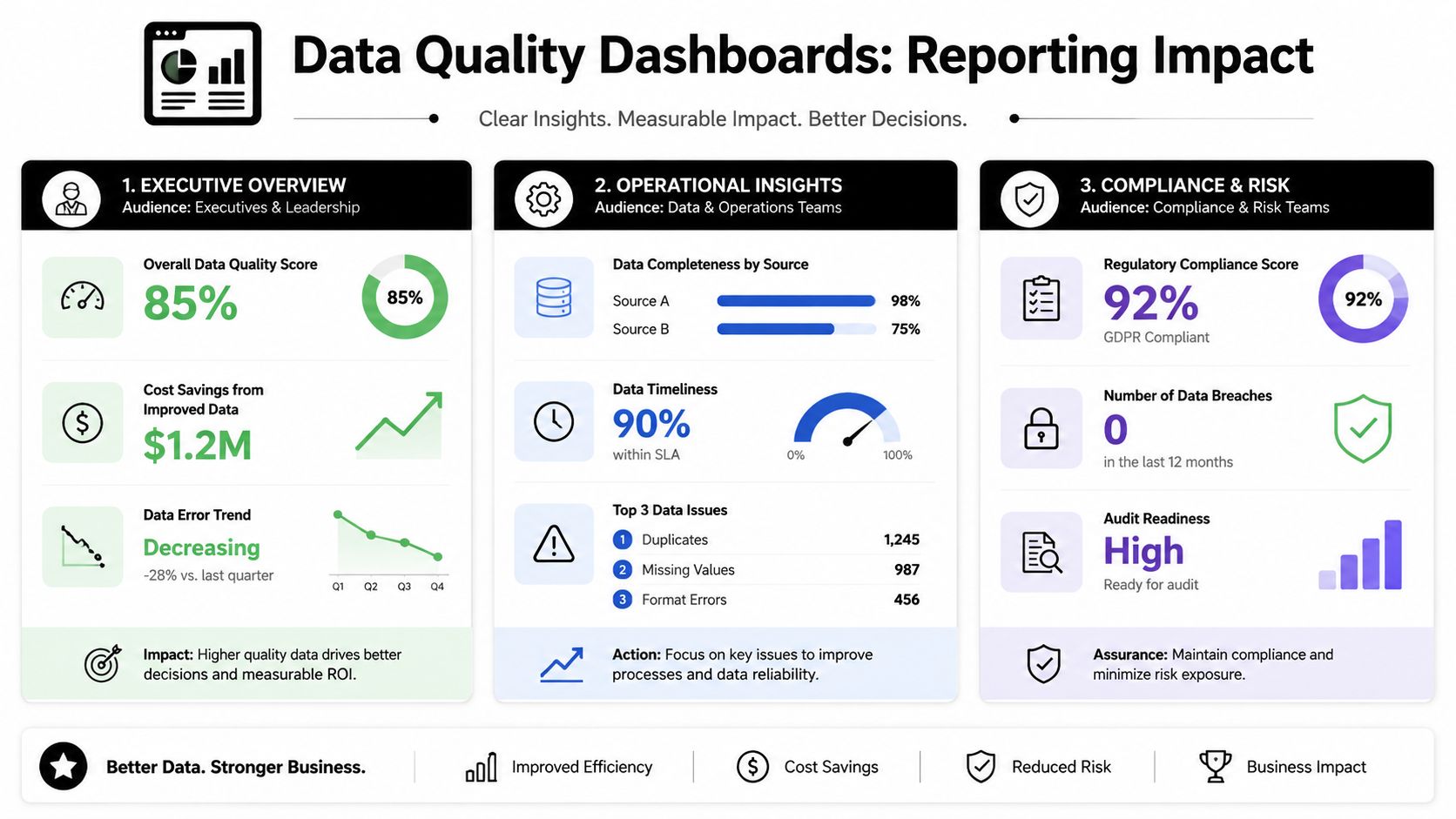
RevOps and sales dashboard
A revenue-facing dashboard should answer one question fast: can the team trust the records driving pipeline execution?
Useful views often include:
| Metric | Why sales and RevOps care |
|---|---|
| Lead data completeness | Incomplete records break routing, prioritization, and segmentation |
| CRM duplicate rate | Duplicate accounts distort ownership, activity history, and forecasting |
| Bounce trend | Contact quality affects outbound execution and sender confidence |
| Routing exception queue | Shows where operational issues are delaying follow-up |
A common scenario is a sales leader asking why rep conversion differs so sharply by territory. The dashboard may reveal that one region is receiving lower-completeness leads or a higher share of duplicate accounts. That changes the conversation from rep performance to data fairness and assignment quality.
Product dashboard
Product teams care less about CRM hygiene in the abstract and more about whether profile data is usable for onboarding, lifecycle messaging, and activation analysis.
A practical dashboard often tracks:
- User profile enrichment coverage: Are accounts and users classified well enough for segmentation?
- Missing critical attributes: Which records lack role, company, plan, or industry context?
- Freshness of account metadata: Can lifecycle campaigns still rely on account details?
- Mismatch alerts: Where product and CRM identifiers no longer align
The dashboard matters when growth and product teams try to personalize onboarding or in-app messaging. If user records are thin or inconsistent, teams assume the experiment failed when the targeting failed first.
Product analytics often look like behavior problems when they're actually identity and profile quality problems.
SRE and operations dashboard
Operations teams need a different lens. They care about reliability, lag, and integration health.
For them, a quality dashboard often highlights:
- Data freshness lag: How long key objects take to reflect source changes
- Integration failure patterns: Which jobs or syncs are introducing quality degradation
- Schema change alerts: Where upstream changes may break downstream assumptions
- API health for data movement: Whether services feeding business systems are stable enough to trust
A practical use case is incident prevention. If a sync starts failing unnoticed, sales may not notice until lead routing slows or fields disappear from views. Ops sees the warning signs earlier when freshness and API health are visible.
The best dashboards don't try to impress with complexity. They help each team answer a specific operational question: can I act on this data today without creating risk for revenue, customer experience, or reporting?
Conclusion The Linchpin of Data-Driven Growth
A Data Quality Manager is often hired to fix a mess. The better reason to hire one is to prevent growth systems from degrading in the first place.
This role protects more than accuracy. It protects sales capacity, marketing efficiency, product relevance, and leadership confidence. When customer and prospect data is complete, consistent, and trustworthy, teams move faster because they stop second-guessing the basics. Routing works. Segmentation holds. Forecasts become more defensible. Automation becomes safer to scale.
The companies that treat data quality as back-office hygiene usually end up paying for it in pipeline friction and reporting disputes. The companies that treat it as a strategic operating function build cleaner workflows, stronger accountability, and better decision-making across the business.
If you're hiring for this role, hire for commercial judgment and systems thinking, not just cleanup skills. If you want to grow into it, learn how data affects revenue, not only how tables are structured. And if you already work with a Data Quality Manager, involve them earlier. The highest-value work happens before bad data reaches the dashboard.
If your team needs cleaner prospect and customer records before they hit campaigns, routing rules, or outbound sequences, Icypeas helps enrich, verify, and operationalize professional data at scale. It's a practical fit for RevOps, sales, marketing, and product teams that want fewer bad records, lower bounce risk, and more usable data flowing into the systems that drive pipeline.









































.png)



.webp)